


May 19 | 6 min read
Introducing an Operator for Cortex
Simão Reis

A standalone, open source operator for Cortex on Kubernetes
Cortex already goes far beyond what most cloud native projects do. It is horizontally scalable, highly available, and can leverage S3 for long-term retention out of the box. You can get started locally or even in a Kubernetes cluster with a single binary/container. But as is usually the case, things get more complicated at scale.
At Opstrace, we have invested a lot of time into operating Cortex, orchestrating it with code as part of our larger observability distribution. We have a powerful, well-tested CI and production environments that give us confidence in making changes and performing upgrades rapidly.
Now that we have developed this deep expertise, we feel confident in our ideas for running Cortex and want to share that experience back to the community in a smaller more digestible form than via our full distribution. So we are reimplementing our existing Typescript code as a standalone operator for Cortex: opstrace/cortex-operator. In our experience, having smaller pieces of software that do one job well not only are easier to maintain and test but they also make it easier for others to adopt it for their own projects and contribute. Over time this should hopefully make it easier for newcomers to learn about Cortex and run it safely at scale.
Why use a Cortex operator? Cortex requires more orchestration than Prometheus because it deploys many different resource types to accomplish its job. A common way to run Cortex is to use the Helm chart. It’s an easy way to get started, but for longer-term operations you really want running code. Using the operator pattern we can do a lot, for example: scale individual Cortex components safely, control rollout logic, and recover from failures with a non-trivial sequence of operations. The end result should be as easy as running Prometheus with the prometheus-operator.
This initial version reads a spec and then generates the appropriate Kubernetes definitions for Cortex:

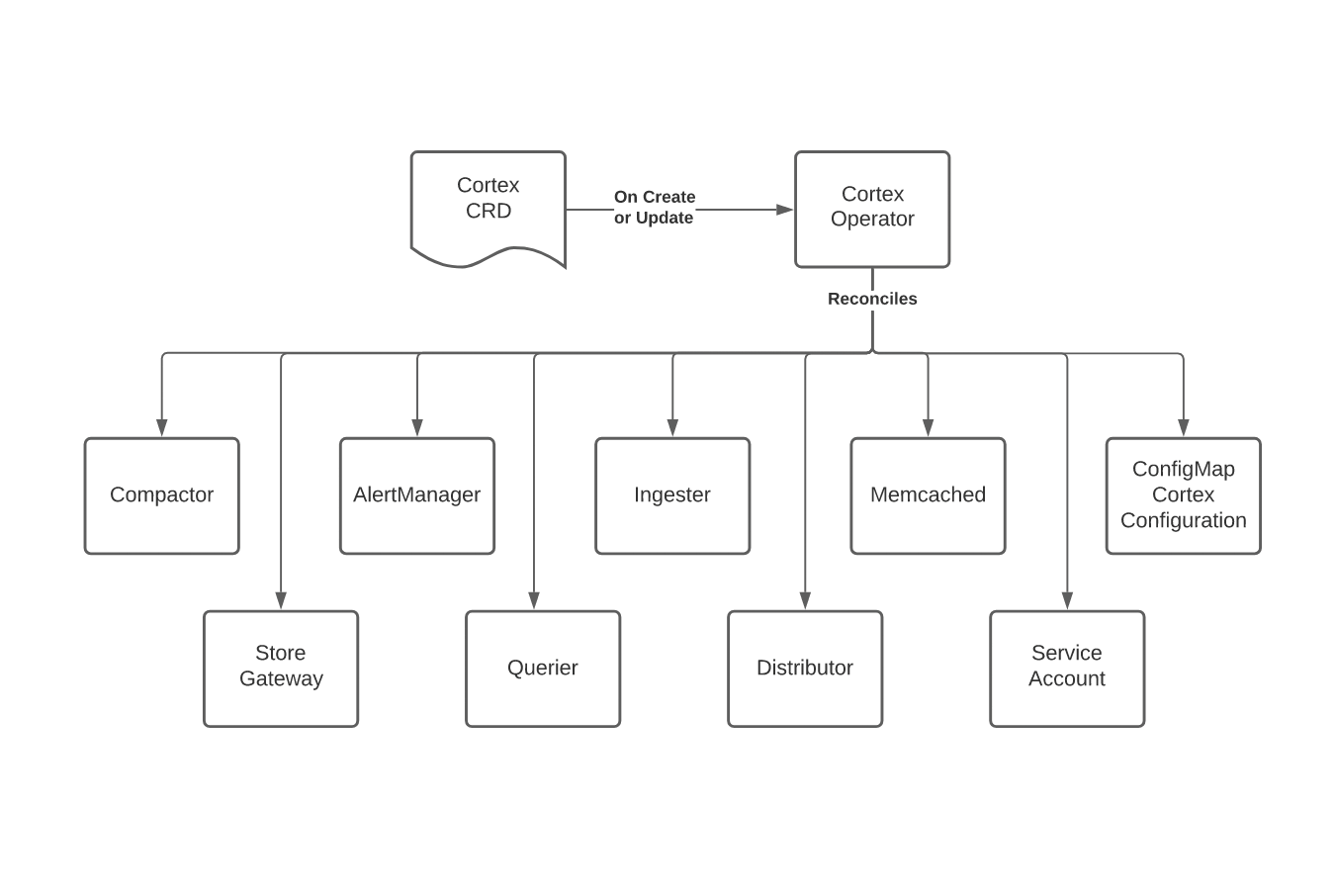
It is built with Go, using the kubebuilder framework. When you create a CRD object the controller creates a ConfigMap with some default configuration for Cortex and deploys all the required services for you. When you update the CRD, the controller reconciles all the necessary resources.
Here’s an example of what you can do today to deploy Cortex on your EKS cluster after you install the operator. We have a guide to scaffold the infrastructure on AWS using Terraform.
First, create a manifest file with the CRD object:
$ cat cortex-sample.yamlapiVersion: cortex.opstrace.io/v1alpha1kind: Cortexmetadata:name: cortex-samplespec:image: "cortexproject/cortex:v1.9.0"blocks_storage:backend: s3s3:bucket_name: cortex-operator-example-209f-dataendpoint: s3.us-west-2.amazonaws.comruler_storage:backend: s3s3:bucket_name: cortex-operator-example-209f-configendpoint: s3.us-west-2.amazonaws.comalertmanager_storage:backend: s3s3:bucket_name: cortex-operator-example-209f-configendpoint: s3.us-west-2.amazonaws.com
Create it using kubectl with the following command:
$ kubectl create -f cortex-sample.yaml
You can see that all the pods are running with kubectl get pod:
$ kubectl get podsNAME READY STATUS RESTARTS AGEcompactor-0 1/1 Running 0 2m59scompactor-1 1/1 Running 0 2m46sdistributor-db7f645c7-2bzlj 1/1 Running 0 2m59sdistributor-db7f645c7-2n22k 1/1 Running 0 2m59singester-0 1/1 Running 0 2m59singester-1 1/1 Running 0 1m26smemcached-0 1/1 Running 0 3mmemcached-index-queries-0 1/1 Running 0 3mmemcached-index-writes-0 1/1 Running 0 3mmemcached-metadata-0 1/1 Running 0 3mmemcached-results-0 1/1 Running 0 3mquerier-7dbd4cb465-66q95 1/1 Running 0 2m59squerier-7dbd4cb465-frfnj 1/1 Running 1 2m59squery-frontend-b9f7f97b7-g7lsf 1/1 Running 0 2m59squery-frontend-b9f7f97b7-tsppd 1/1 Running 0 2m59sstore-gateway-0 1/1 Running 0 2m59sstore-gateway-1 1/1 Running 0 2m34s
When all the pods are running you can start sending metrics to Cortex.
Using this sample manifest you can deploy Prometheus node-exporter to the cluster to gather node metrics and scrape them with Grafana Agent. To confirm Cortex is receiving metrics you can set up port-forwarding and then use cortex-tools to read them back.
Set up port-forwarding with kubectl:
$ kubectl port-forward svc/query-frontend 8080:80
Query with cortex-tools with:
$ cortextool remote-read dump --address=http://localhost:8080 --remote-read-path=/api/v1/readINFO[0000] Created remote read client using endpoint 'http://localhost:8080/api/v1/read'INFO[0000] Querying time from=2021-05-19T12:25:29Z to=2021-05-19T13:25:29Z with selector=up{__name__="up", instance="ip-10-0-0-42.us-west-2.compute.internal", job="monitoring/agent", namespace="monitoring"} 1 1621430648242<... snip …>
You can also deploy Grafana and
add a datasource
pointing at the query-frontend service running at the url
http://query-frontend.default.svc.cluster.local/api/v1/read.
We decided to open the repo as soon as possible so you can follow along from the very beginning stages of development. Currently, the operator is only tested on EKS with the blocks storage engine using the Amazon S3 backend. When we finally integrate this with Opstrace we will leverage our testing infrastructure and production customers to provide even more confidence in the operator.
What’s next for this operator? First and foremost, we want to engage with the Cortex community. We’d like to discuss it with you wherever you like, in our community channels or the #cortex channel at CNCF. Please join us so we can work together to build something useful for everyone. And there are many more features to be built. On our roadmap are several important areas, including:
- Custom Cortex configuration and upgrade support are in progress.
- Reflect status of deployment in CRD status field.
- Add Kubernetes validation webhook for Cortex config. (For example, did you set all the required options to set up the S3 storage correctly?)
- Improve local testing with a tutorial for Kubernetes Kind cluster and minio.
- Support CRDs to deploy Cortex in a particular topology. Currently, Opstrace deploys N Cortex ingesters, distributors, and queriers, but does not distinguish between instances; our goal is to be able to handle other ingestion and query load patterns in the same cluster.
- Advanced failure remediation, for example, removing a component from the ring and re-create it.
Cortex is an amazing, growing project that offers a lot of value. We want to contribute our Cortex expertise back to the community in the form of a Kubernetes operator to make it easier for more people to join the Cortex community. Get started with our quick start here: https://github.com/opstrace/cortex-operator/#quickstart