


Jun 3 | 2 min read
Introducing the Ring Health UI for Cortex and Loki Components
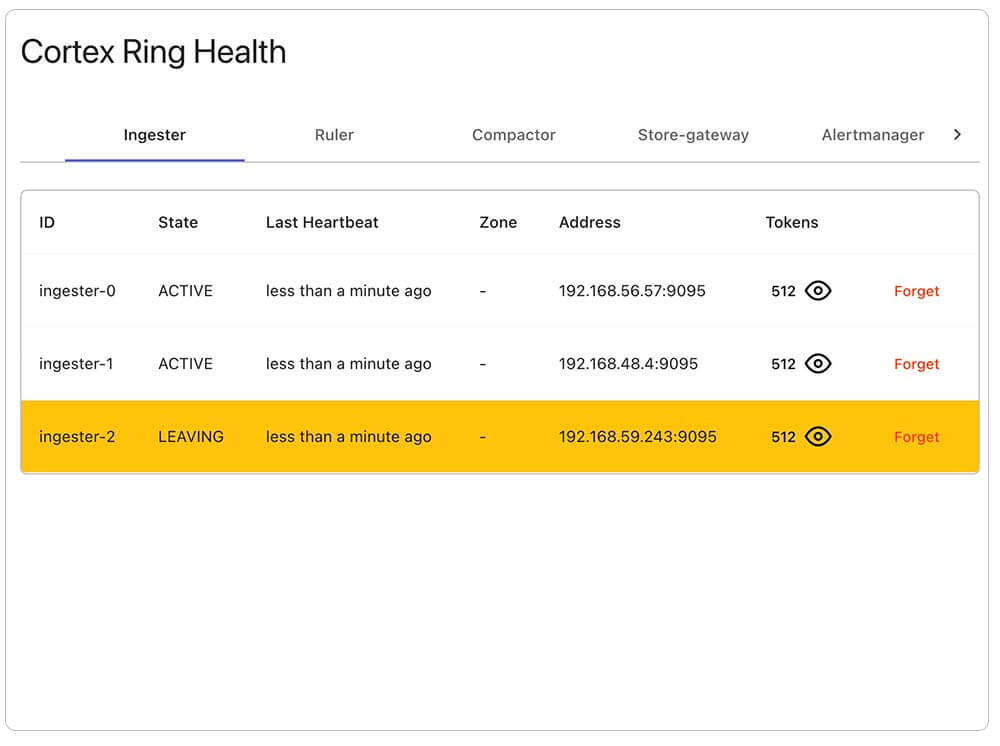
Critical ring information is now centralized and actionable from a variety of disparate sources
When running Cortex and Loki—as we do with Opstrace—there are many (many) running containers. Several of these services (ingester, store-gateway, compactor, ruler, and alertmanager) use a hashring [1][2] to coordinate work-sharing and discovery.
In the happy path, you never need to look at the state of the ring members because members will join, leave and redistribute tokens automatically as components come and go during scaling or failover. However, when troubleshooting, access to this information is critical to guide your effort in the event that the system is behaving unexpectedly. Our new UI presents all of the services’ ring information to you in a centralized way, collecting the data from various disparate endpoints (on both Loki and Cortex):

It’s a great starting point to check if components are in good shape via this new UI. It’s possible that some components, like an ingester, might get stuck in a state other than ACTIVE and they need to be forgotten and restarted in order for the work (allocated through token assignment) to be redistributed to healthy ingesters. We allow you to do this manually from the UI. Sometimes, though, components will fail and recover on their own:
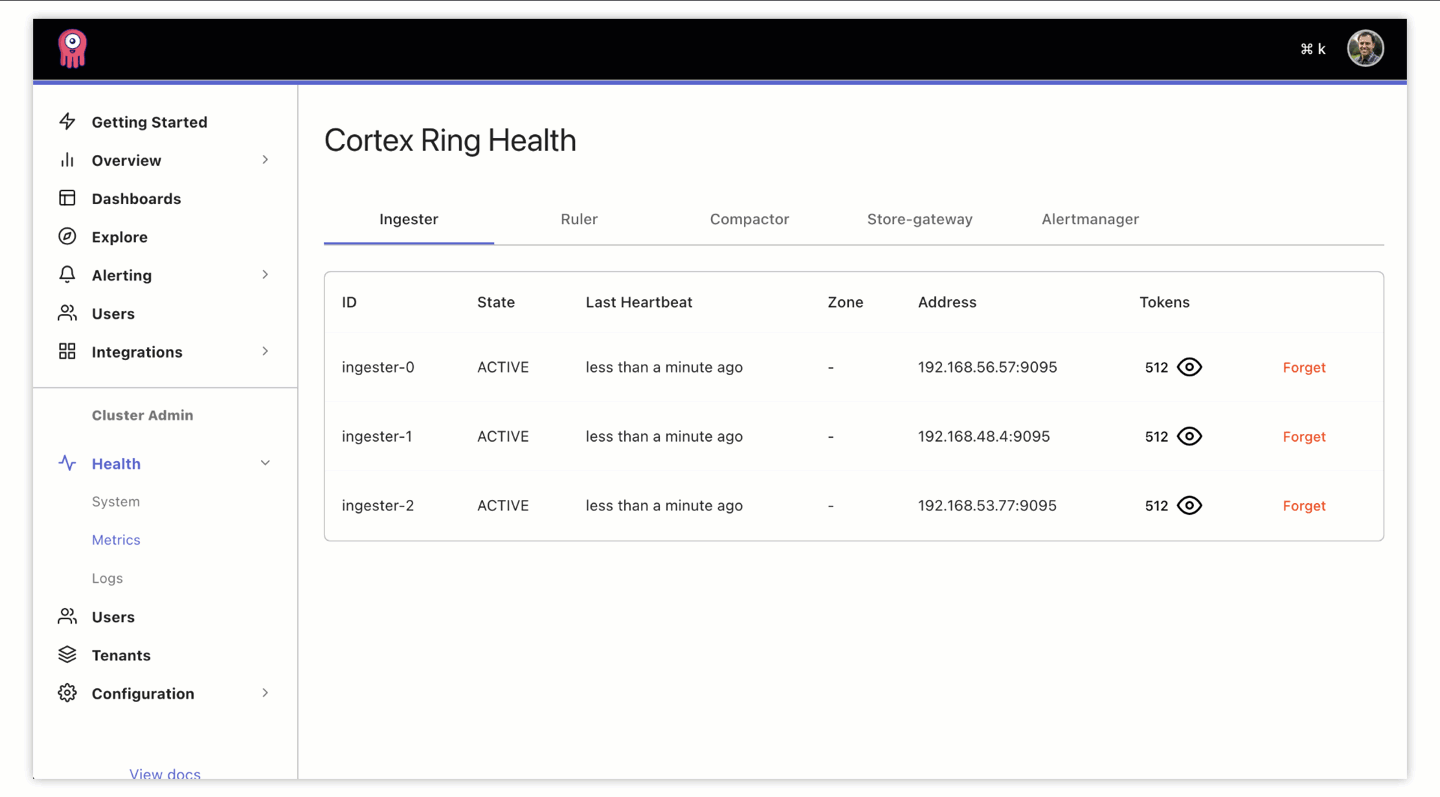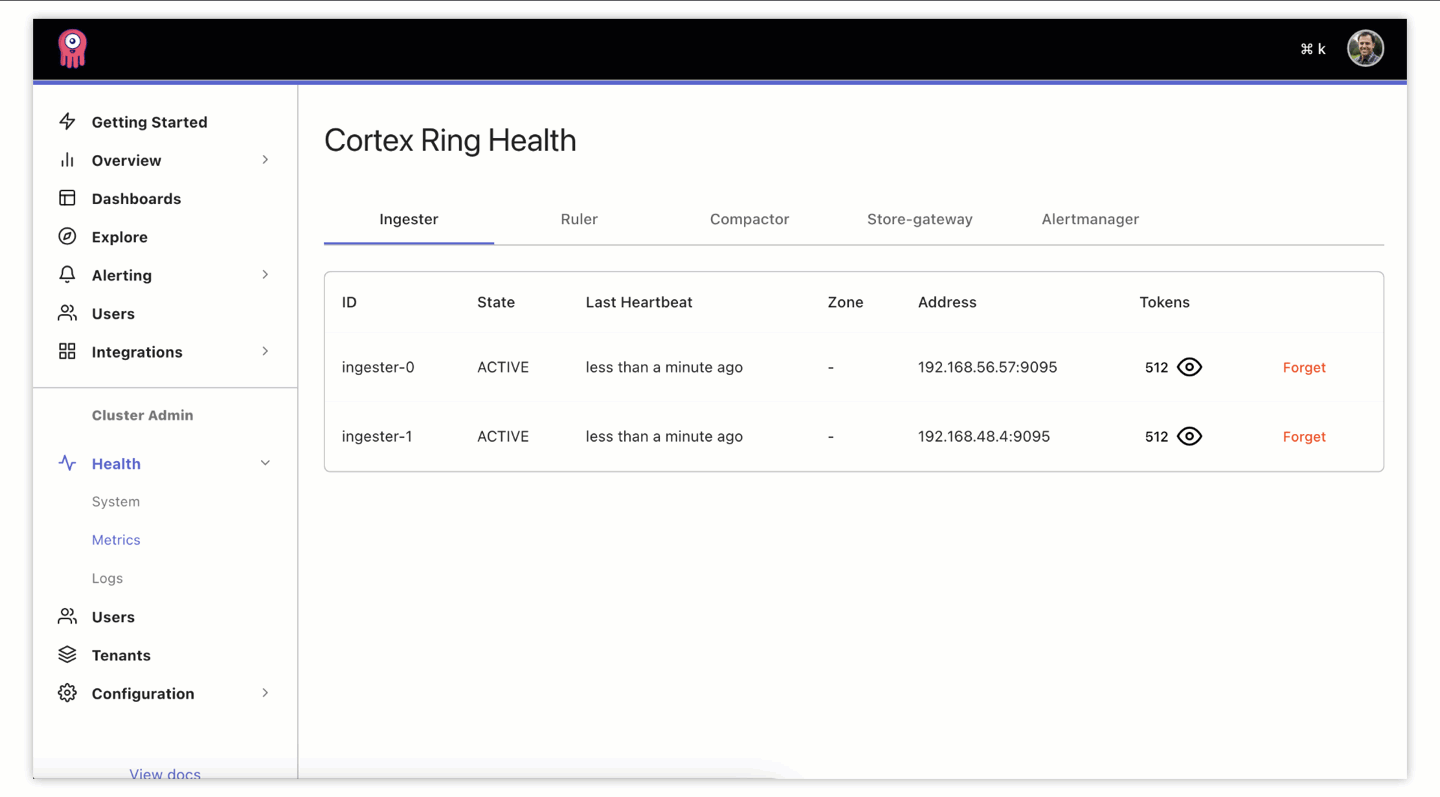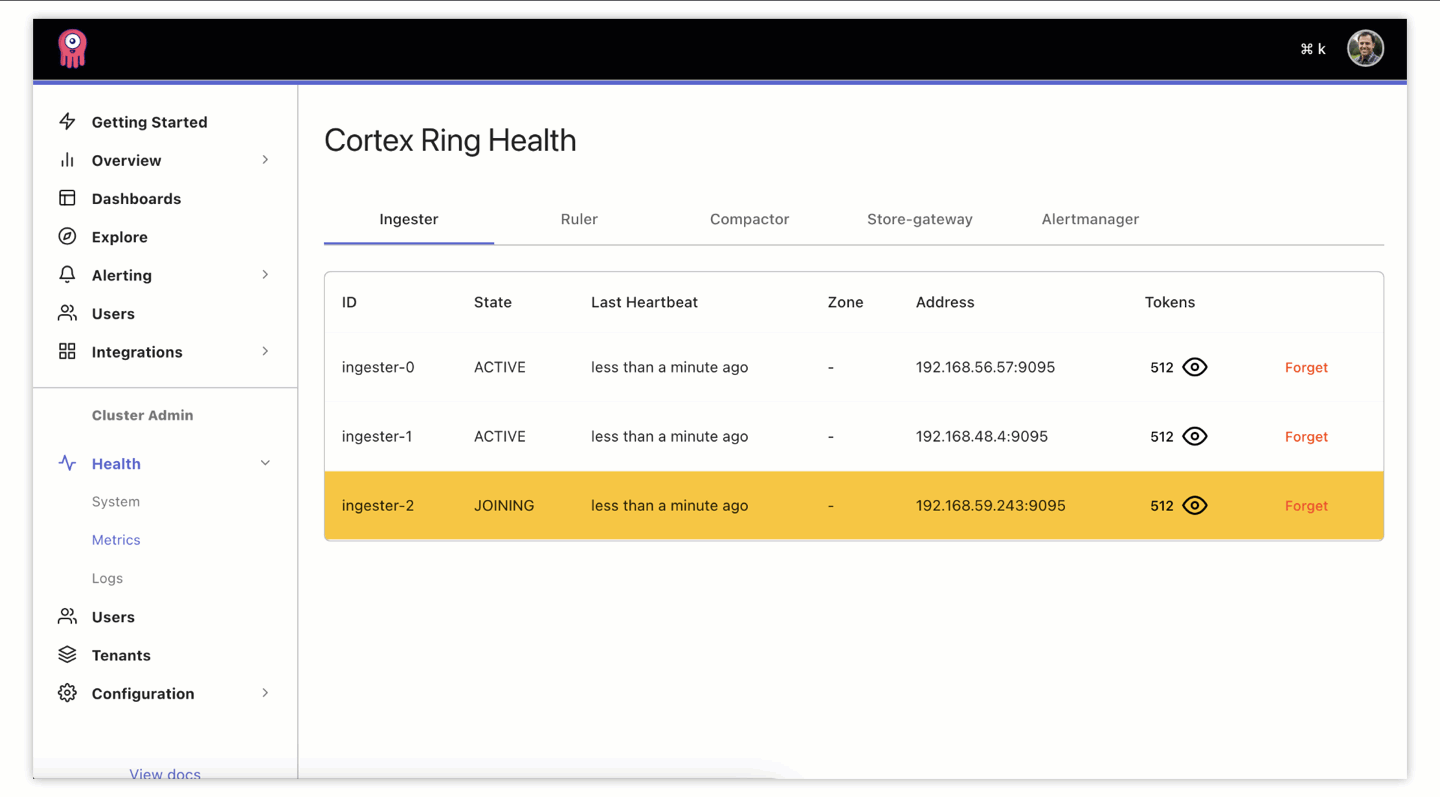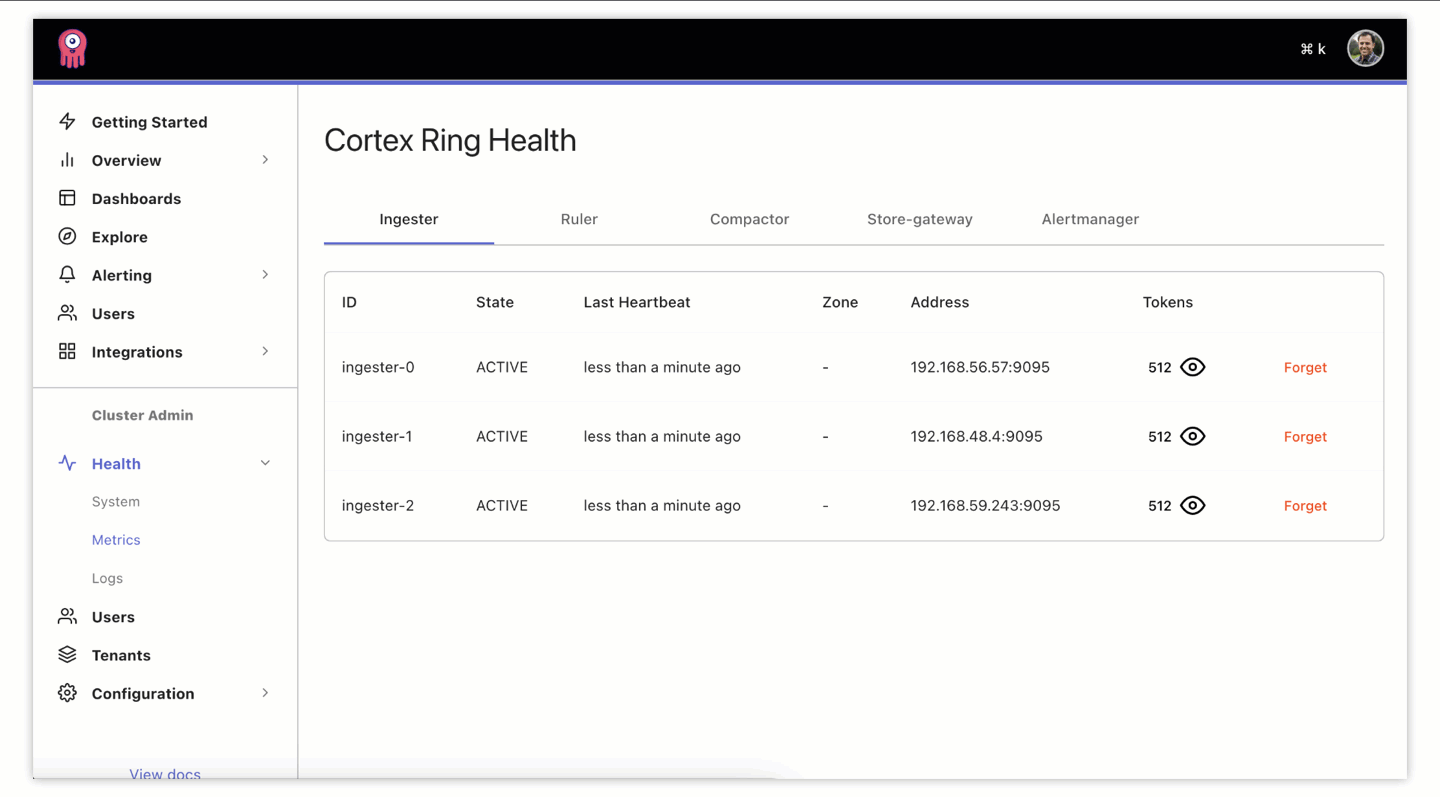
Looking ahead, this manual remediation can be improved through automation. We
recently announced a
cortex-operator project where
we intend to do just that—the identification and remediation of ring issues to
eliminate the need for manual intervention. Join our
community channels if you’d like to follow our
progress.
[1] Cortex ring architecture and getting started: https://cortexmetrics.io/docs/architecture/#the-hash-ring https://cortexmetrics.io/docs/guides/getting-started-with-gossiped-ring/
[2] Blog post from Grafana Labs: https://grafana.com/blog/2020/03/25/how-were-using-gossip-to-improve-cortex-and-loki-availability/