


May 20 | 3 min read
Open Source Kubernetes Collection in Less Than One Minute
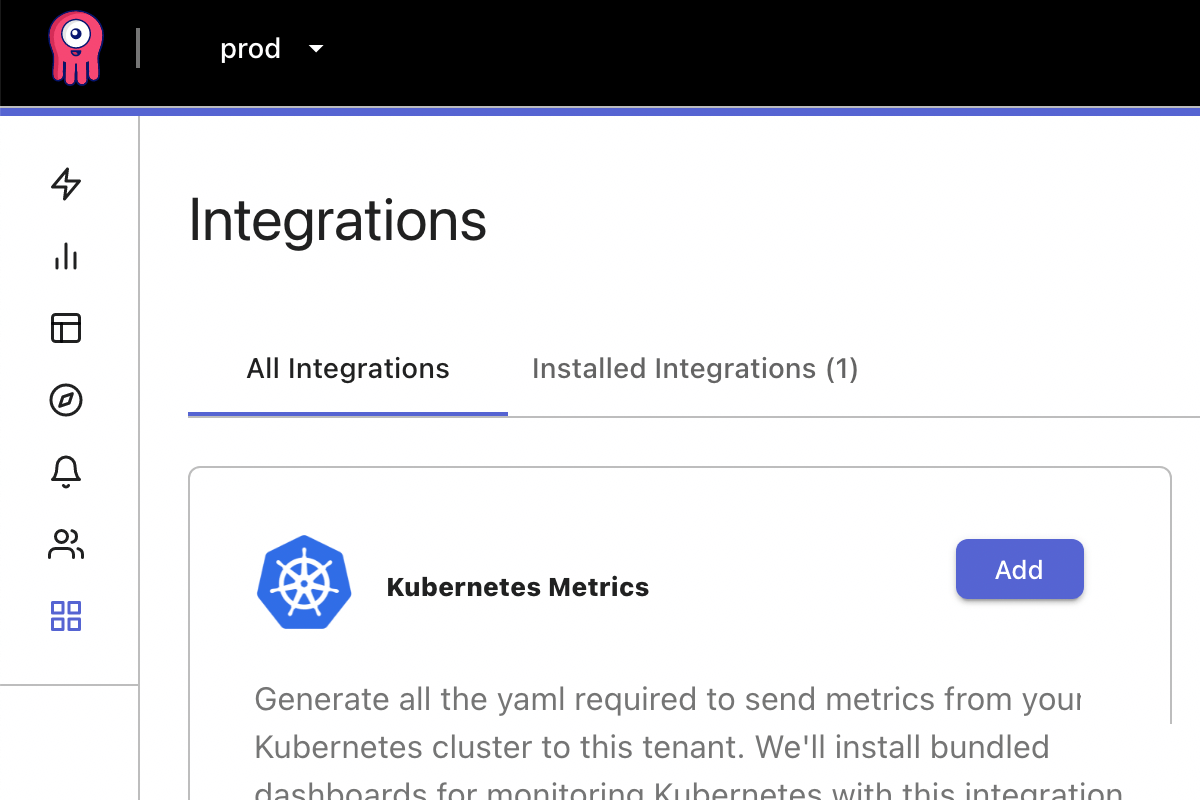
One step to collect, visualize, and act
Announcing our first integration that ingests metrics from Kubernetes. It takes about 1 minute to set up:

As you can see from the GIF, it’s straightforward to collect and use data from Kubernetes. This integration is open source (like everything we do) and automatically configures the collection agent to use our secure API endpoints. It’s also multi-tenant, which means you can configure different Kubernetes clusters to send their data to different Opstrace tenants (e.g., “prod,” “staging,” “dev”).
But let’s back up for a second and consider why integrations are important. What’s the first thing you need to do after you stand up any monitoring tool? You want to collect data from all your different data sources. When you do it yourself with open source observability projects—vs. paying an arm and a leg to some big vendor—you have to piece together the end-to-end data collection yourself. Typically you’ll scour the internet to compose various required components (using trial-and-error to find the ones that work). It is, of course, doable, but for any engineer, it’s toilsome. Furthermore, when it comes time to upgrade all of those pieces, how do you know that they will continue to work together? We’re putting an end to this toil and uncertainty.
When you install an integration in the Opstrace UI, you’re prompted with a simple interface. This interface provides a user-intent view of the collection story: collection, visualization, and action. Behind the scenes, the details of the implementation for that specific integration will wire up the necessary components for you:
- Collection: choose the right agent for the job with the right config. For example, deploy an agent in your Kubernetes cluster or launch exporters in Opstrace to fetch data from other services, such S3 metrics via CloudWatch.
- Visualization: provided dashboards present the most common data to you quickly. For example, the Kubernetes integration installs default dashboards.
- Action: reasonable default values based on best practices that you can tune so you can take action when something goes wrong.
Additionally, multi-tenancy is supported out of the box. In the GIF above, you will notice we first selected the “prod” tenant to install our integration. Each tenant has a standalone Grafana instance, and in the future, integrations will support optional synchronization across tenants.
This Kubernetes metrics and logging integration is just the first step. We’re building a comprehensive catalog of common services, so onboarding and upgrading are easy and reliable. Big vendors have had integrations for a long time, but now you—when doing open source observability—have them too.
Let us know which integrations you’d like to see next or if you’d like to work on an integration with us!