



Apr 29 | 3 min read
Toward High-trust, Zero-downtime Upgrades
Simão Reis

Tested, reliable, upgrades for the Open Source Observability Distribution
Open source observability can be a lot of work to set up yourself, but it can be even more work to keep it up-to-date with the latest releases of the various components. Our goal is to release often and to calm the fears of any team that has been bitten by wonky software upgrades in the past. We’ve been there ourselves, and we know just how hard it is to build a product where people trust the upgrade process. Building high-trust upgrades is perhaps the most important part of an observability distribution, which is why we’re investing heavily in a simple, reliable upgrade process. In this blog post, we will describe our goal for zero-downtime upgrades, where we are today, and invite you to help on future work if you’re interested.
We all know upgrades are important because they bring us new features, improve existing features, and patch security vulnerabilities. But as system complexity increases, upgrades become more challenging. If you have experience composing a monitoring stack from disparate open source components, you may be upgrade-cautious due to past downtime experiences caused by the upgrade process or component incompatibility due to API changes. It may have left you worried about further downtime, effort, and uncertainty of whether it will work when it comes back up.
We aim to address these concerns by making upgrades for open source
observability transparent and seamless—that is, they just work. Zero-downtime
upgrades are our north star. We believe upgrades should be effortless,
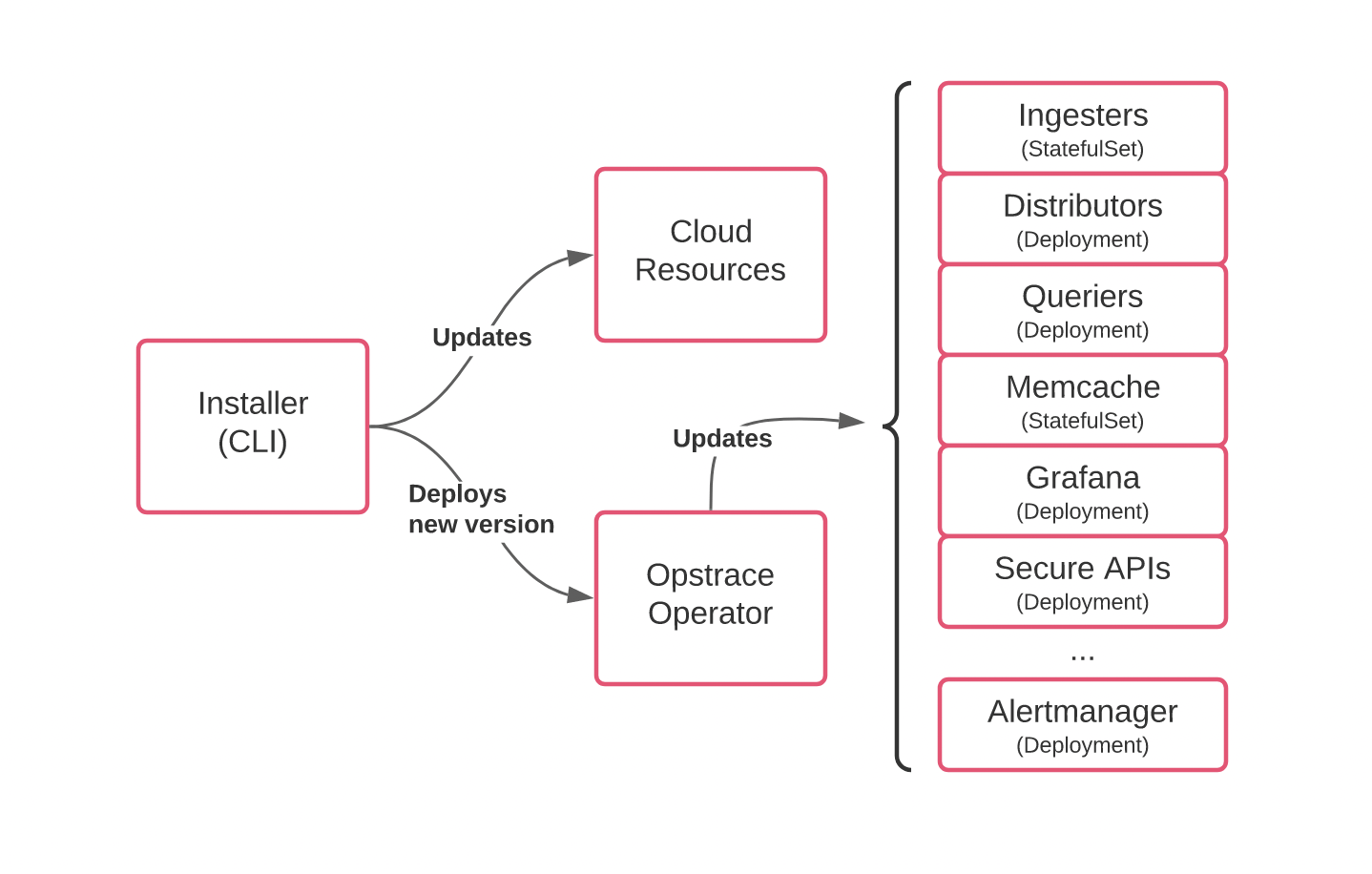
resilient, and support seamless rollbacks. To begin, we built a simple
opstrace upgrade subcommand that updates cloud resources and deploys an
updated version of the Opstrace operator, which in turn updates the components
of the system:

Reliable, zero-downtime upgrades are only possible if you have a process for repeatedly testing and catching issues or regressions early. So we built an extensible CI pipeline. As with any CI pipeline, we have discovered several problems (for example handling older cluster config versions) and remediated them before upgrading any customer in production. A repeatable pipeline to test upgrade correctness, upgrades under load, and detect regressions is the critical foundation of our future work.
Right now we manage all upgrades for our users, so we keep track of which version they are currently running and which version we can upgrade them to. Our next step is to codify this into releases, so through a simple CLI subcommand, anyone can see that an upgrade is available for the current released version that they are running.
Making upgrades reliable and easy is core to what our open source observability distribution is. The topic of zero-downtime upgrades is a big one, and just like any feature, there is a lot of ongoing investment to cover new or unforeseen edge cases. This post was just an introduction to the topic, and you can expect many more blog posts in the future. We're just at the beginning of a long journey, and we invite you to participate in it with us.